

You did it!
Your writers have crafted a series of killer blogs and articles that really resonate with your target audience. You made sure they are informative and unique, and they keep the reader's interest while still helping to sell your product. The SEO is on point, with the keywords you researched intentionally sprinkled throughout, appearing enough to feature highly on search engines without feeling forced and awkward.
You finally hit 'Publish' and… nothing. You had a flurry of interest at first, but then when you search for your posts a few days later you can’t even find your content, never mind about having it appear at the top of the results. You are completely at a loss. Did you miss something? Or even worse, did you completely tank this entire campaign?
The good news is, this is not your fault. In fact, this probably happened because you created some really great content, and as a result, you have become the victim of web scraping.
The bad news is that this can be devastating for any digital marketing campaign, and needs to be handled immediately. If you don’t solve this quickly, you could actually end up with less traffic and a lower conversion rate then before the campaign started. Yikes.

What Actually is Web Scraping?
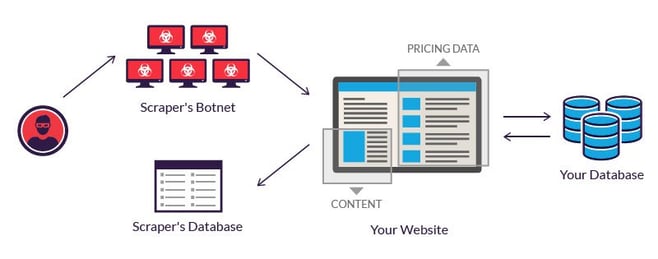
Content web scraping is a process where fraudsters use bots to “scrape”, or steal, your high-quality, keyword-rich content and publish it on their own websites. This is a growing problem because it has become very easy for anyone to scrape content online. A quick search on Google will provide a quick "how-to" for even the most computer illiterate thief to steal your intellectual products. Web scraping is no longer reserved only for tech-savvy "hackers" capable of programming malicious bots themselves. Almost anyone can do it.
After running a scraping script on your website, the fraudster will have access to all of the content you spent untold hours curating. This is not limited to just the words on the page, either. A sophisticated scraper bot can also acquire any images, formatting, and links included on the page. All your hard work is wrapped up with a nice bow and delivered to the fraudster.
Once they have acquired this information, they generally use it in one of two ways. One way is to repurpose and edit to post on their own website, stealing your traffic. More commonly though, they will copy and paste it on dozens of trash websites that exist solely to duplicate content.
Why is it So Bad?
It is obvious how the first use of your stolen data damages your business, brand, and reputation. There are only so many people looking up each topic and if someone steals your content, they are also stealing a chunk of your audience. This translates to fewer clicks, fewer leads, and ultimately fewer conversions. In this way, content thieves directly take money out of your pocket and harm your campaign.
The second way is a little more complicated. Understanding requires a bit of basic understanding of how search engines work, and what Search Engine Optimization (SEO) actually is. The internet has access to a vast amount of information and search engines attempt to organize and categorize this data using programs called web crawlers.
These crawlers are constantly visiting every page on the internet and indexing them by factors such as content, speed, and usability. Ultimately, the goal of this is when people use search engines to search for a particular word or phrase, they are able to provide the most useful pages for that person, allowing the user to achieve their goal as quickly as possible and continue using the search engine.
SEO is the process of optimizing a given website or page so these crawlers determine the content is helpful, given the relevant searches. The most obvious way this happens is by ensuring certain keywords related to a particular topic are included in the content of said page. Another way is to provide content that directly addresses the reader's concern. Keywords have evolved into more general questions; if you can answer someone's question quickly and efficiently, SEO increases.
There are dozens of other ways search engines rank results, however, an integral one of these is uniqueness. Nobody wants to read through page after page of repeated information, so crawlers will filter out duplicate content. You might think this means the crawlers will disregard all of those nasty duplicates and leave your page to its rightful place in the search results, but unfortunately, that's not always how it works.
Crawlers cannot always identify which content is original and which is stolen; they may even think that your page is the stolen content and one of the copied pages is the original - resulting in punishment. Most often, they cannot tell the difference at all, so they punish all pages equally, sending them tumbling down the results list into obscurity. This allows your competitors to appear higher up on the list by default, taking away business and damaging your brand.
While both of these can do irreparable damage to your campaign, what is even more insulting and destructive is those using web scraping in order to do both attacks simultaneously. By altering your content just enough to maintain uniqueness for themselves, then making your blogs appear to be copied, fraudulent companies can both eliminate their competition and take advantage of all of your research and work at the same time. This can be truly devastating for any small or new company trying to establish itself or maintain its presence.
What Can I Do About It?
Luckily, you and your campaign are not powerless against these scraper bots, and there are legitimate and effective ways to fight back. Many of these techniques you can do yourself! With the methods listed in this article, you can improve your defenses and prevent your content from getting scraped.
For example, by adding CAPTCHAs, you can make it much more difficult for bots to copy your website, as all but the most sophisticated bots are unable to solve them. Unfortunately, however, tools like these, while effective at stopping the fraud, will also likely lose you valuable leads as genuine people may find these defenses tedious and leave for another website. Meanwhile, other solutions offered, such as embedding content with internal links, may act as a small damage reduction but ultimately will not protect your marketing campaign.
As such, the only complete solution is to get a professional ad fraud solution. At Anura, ad fraud is our specialty. With pattern and behavioral recognition, we are able to identify malicious bots far more accurately than even the most sophisticated CAPTCHAs (without blocking real visitors) and are able to do it without any of the timely customer interactions that can cost you conversions. This allows us to intercept web scraping scripts before they are able to copy your content, meaning you can sit back and watch your marketing work its magic.
Anura does not use confusing numerical scoring systems which create false positives. We rely on a black-and-white indicator of web traffic as real or fraudulent. When Anura says it’s bad, it’s bad.
Don’t let yourself become a victim of fraud, request a trial today.
*This blog has been updated in December 2021 with recent information.
